

What happens when you type a url in your browser?
Explained as simply as possible… but not simpler.

You type “google.com” into your browser, hit Enter, and boom - the page loads in milliseconds.
Behind that seamless experience is a carefully orchestrated setup of distributed systems, each performing its role with precision. Understanding this process is fundamental to system design, and it’s why this question shows up in engineering interviews.
Let’s break down exactly what happens, step by step.
URLs
Behind that seamless experience is a carefully orchestrated dance of distributed systems, each performing its role with precision. Understanding this process is fundamental to system design, and it’s why this question keeps showing up in senior engineering interviews.
Let’s break down exactly what happens, step by step.
The Journey Begins: Understanding URLs
When you type a URL like https://www.bbc.co.uk/news/technology into your browser, you’re actually providing four pieces of information:

Scheme (
https://) - Tells the browser which protocol to use. HTTPS means the connection will be encrypted.Domain (
www.bbc.co.uk) - The human-readable name of the server.Path (
/news) - Think of it as a directory in a file system.Resource (
/technology) - The specific file or content you want.
Computers don’t speak in domain names though. They speak in IP addresses - unique numerical identifiers for every device on the internet. So our browser has a problem to solve.
Step 1: DNS Lookup - Finding the Server’s Address
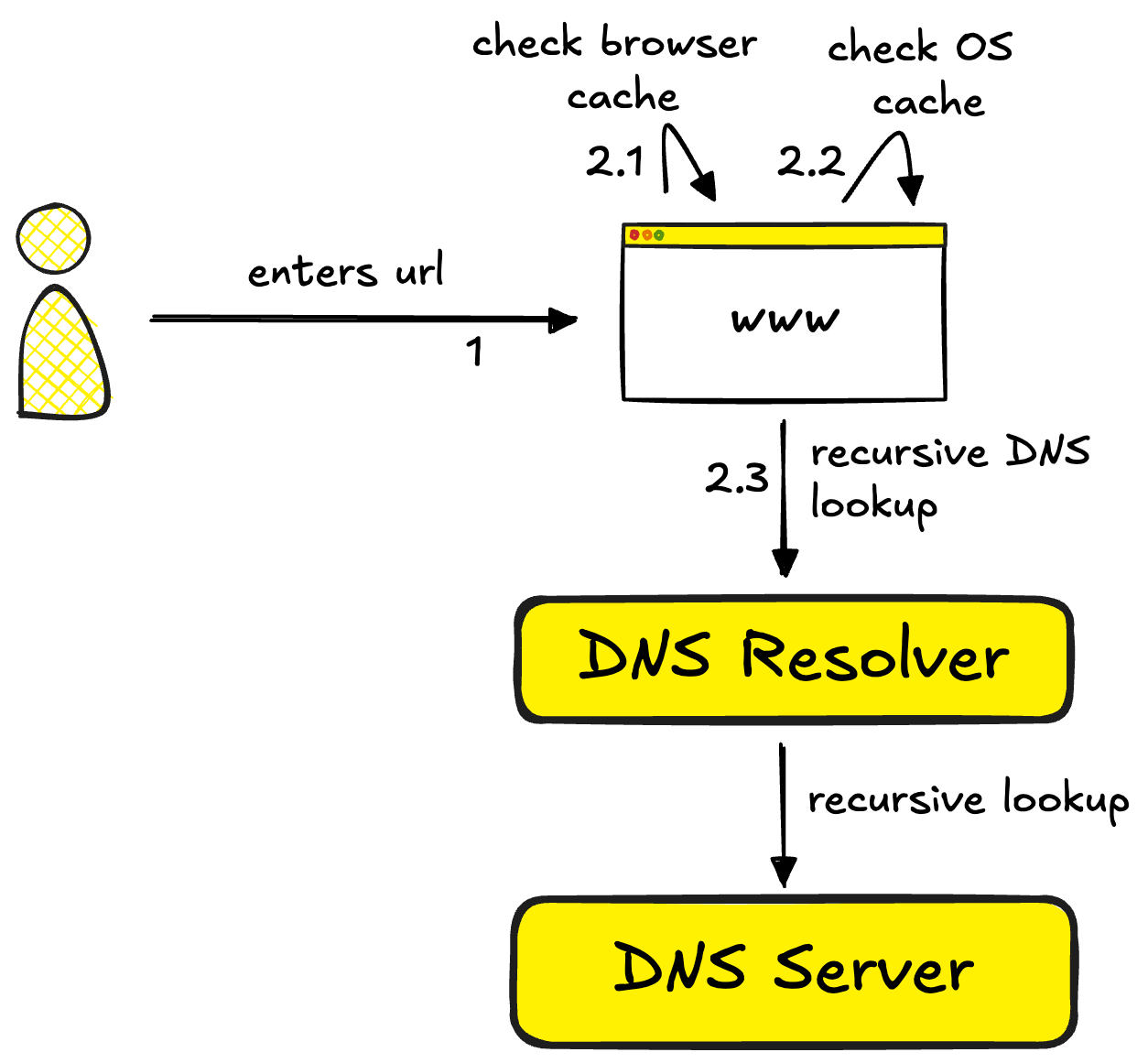
The browser needs to translate “www.bbc.co.uk“ into an IP address. This is where DNS (Domain Name System) comes in - essentially the internet’s phone book.
But DNS lookups can be slow, so the system is designed with multiple layers of caching:
First stop: Browser cache
The browser checks if it recently looked up this domain. If yes, it uses the cached IP address.
Second stop: Operating system cache
If the browser doesn’t have it, it asks the OS, which maintains its own short-term cache.
Third stop: DNS resolver
If neither has the answer, the OS queries a DNS resolver (usually provided by your ISP). This kicks off a chain of requests through the DNS infrastructure, from root servers to authoritative name servers, until the IP address is found.
The answer gets cached at every step along the way, making subsequent requests fast.
Step 2: Establishing a TCP Connection
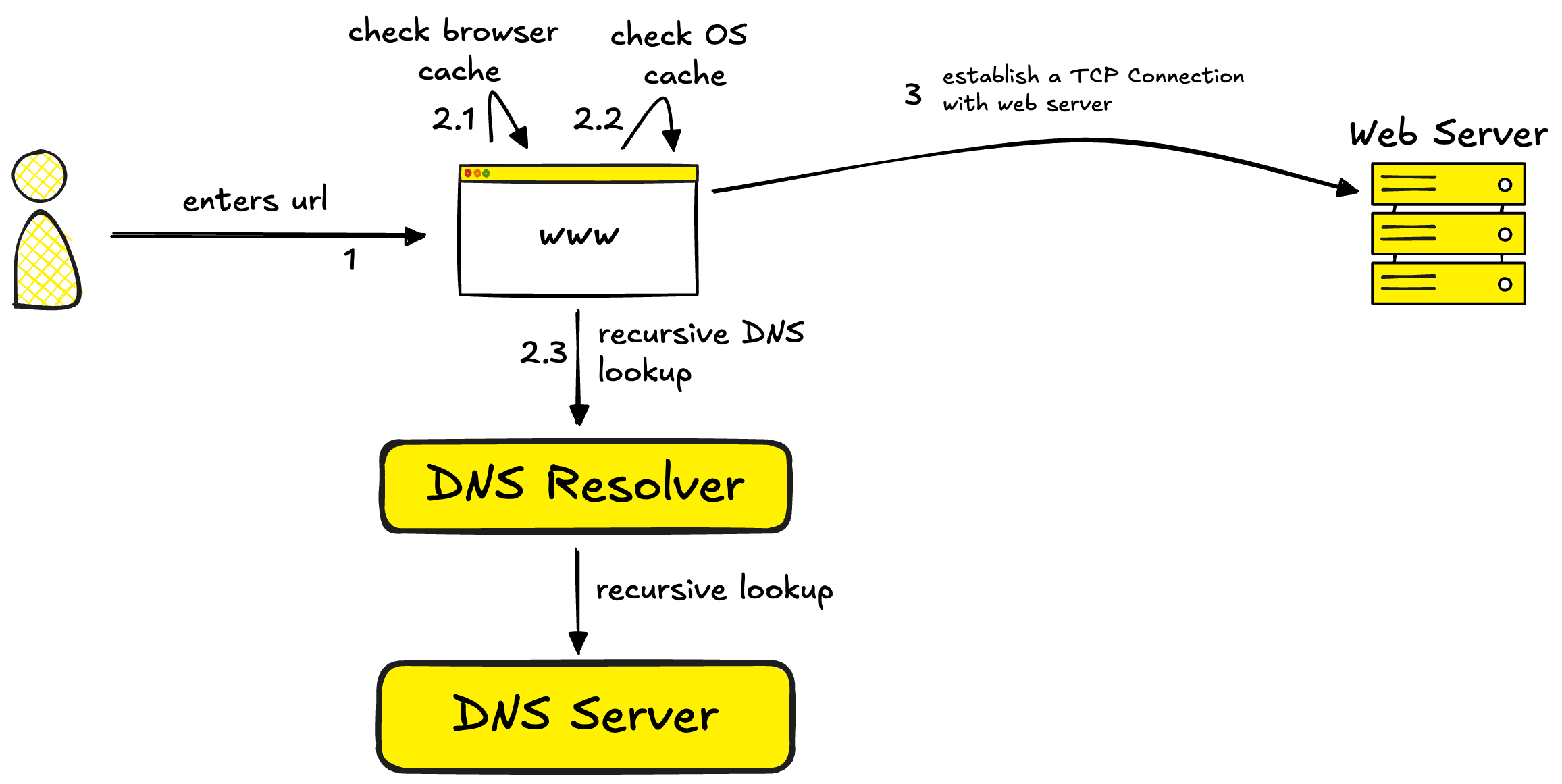
Now that the browser has the IP address, it needs to establish a connection with the server. This happens through a TCP handshake, a multi-step process that takes several round trips across the network.
Modern browsers use something called “keep-alive connections”. Instead of opening a new connection for every request, they reuse existing connections whenever possible. This dramatically reduces latency.
If you’re using HTTPS (which you should be), there’s an additional step: the TLS/SSL handshake. This establishes an encrypted tunnel between your browser and the server, but it’s computationally expensive. Browsers mitigate this cost using SSL session resumption, allowing them to skip parts of the handshake for repeated connections.
Step 3: Sending the HTTP Request
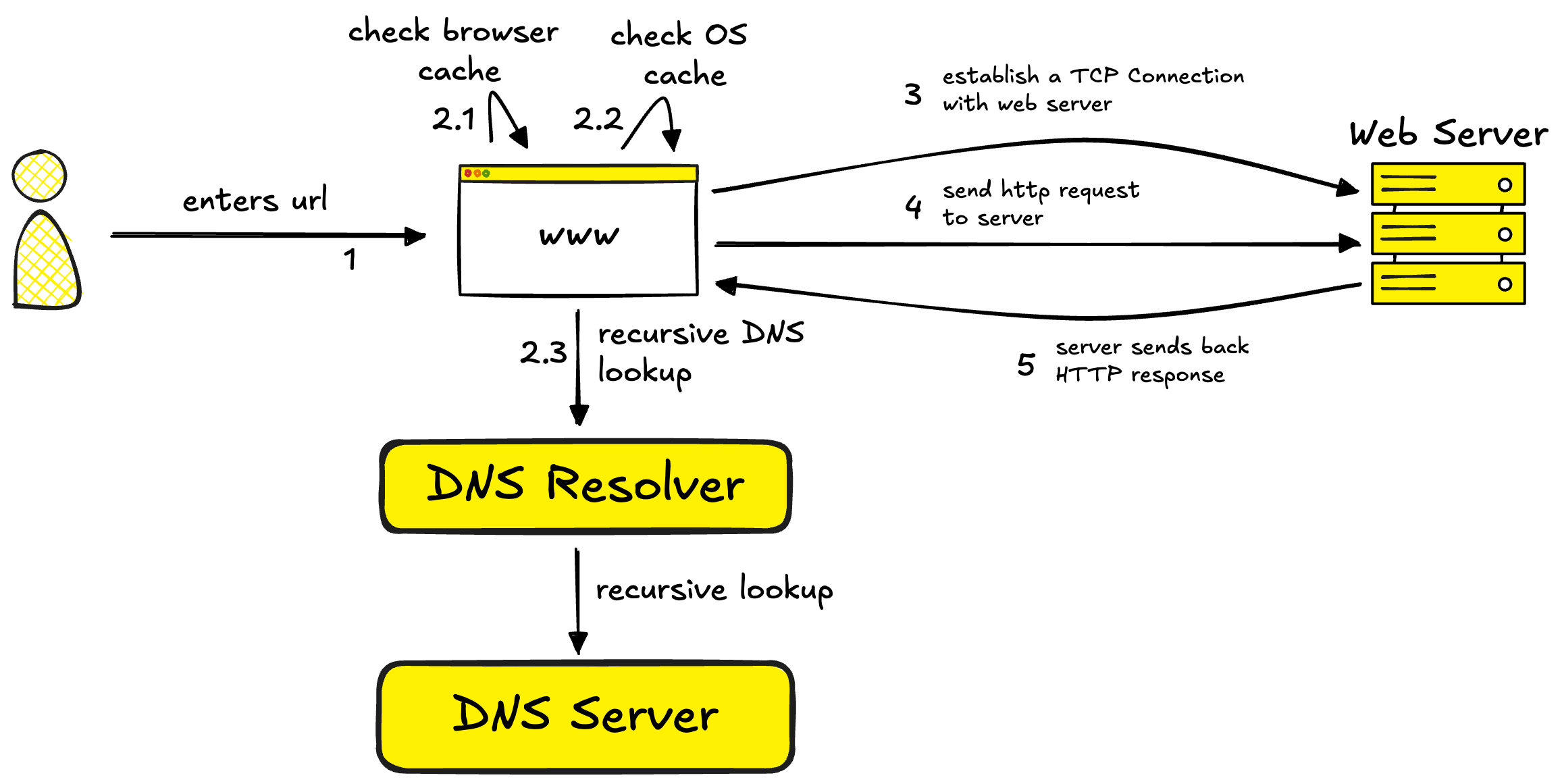
Once the connection is established, the browser sends an HTTP request over it. HTTP itself is simple, just a text-based protocol asking the server for specific resources.
The server processes the request, fetches the necessary files (HTML, CSS, JavaScript), and sends back a response.
Step 4: Rendering the Page
The browser receives the HTML and starts parsing it.
As it reads through the HTML, it discovers additional resources it needs: CSS stylesheets, JavaScript files, images, fonts. For each of these, the browser repeats the entire process:
DNS lookup (likely hitting cache this time)
TCP connection (likely reusing an existing one)
HTTP request
This is why web performance optimization matters so much. Each additional resource means more round trips, more latency, more waiting.
Why This Matters for System Design
This seemingly simple flow touches nearly every fundamental concept in distributed systems:
Caching at multiple levels (browser, OS, DNS)
Load balancing (DNS can return different IPs based on geography)
Latency optimization (connection reuse, SSL session resumption)
Fault tolerance (redundant DNS servers, CDNs)
Scalability (handling millions of concurrent requests)
When you’re designing systems at scale, you’re essentially orchestrating variations of these same patterns. Understanding how they work together in something as “simple” as loading a webpage gives you the mental models you need to design robust, performant systems.
Like posts like this?
You may also like these:




By subscribing, you get a breakdown like this every week.
Free subscribers also get a little bonus:
🎁 The System Design Interview Preparation Cheat Sheet
If you’re into visuals, paid subscribers unlock:
→ My Excalidraw system design template – so you have somewhere to start
→ My Excalidraw component library – used in the diagram of this issue
No pressure though. Your support helps me keep writing, and I appreciate it more than you know ❤️
I like how you turned a huge system into a simple step-by-step story.
Thanks for using easy to understand language. Who really owns the DNS resolution infrastructure and how to handle failure at DNS resolution?